Serverless Is Great, Until You Let Strangers Run Code on Your Machines
Here is something I find genuinely underappreciated in conversations about cloud infrastructure. Everyone talks about how fast serverless is, how it scales to zero, how you only pay for what you use. All of that is true. But there is a much harder question sitting underneath all of it that almost nobody asks out loud.
What happens when the code running on your infrastructure is not yours?
I am not talking about a bug in your own functions. I am talking about a cloud provider scenario, where a stranger submits arbitrary code, you package it up, and you run it on the same physical machine as twenty other strangers' code. That is the actual promise of public serverless. And the moment you start pulling on that thread, you realize that the foundation most people assume is solid is actually pretty shaky.
A team at Nubis PC published a paper on exactly this problem, and their solution involves a technology called unikernels that I think deserves way more attention than it gets. Let me walk you through the whole thing.
research paper link: https://dl.acm.org/doi/10.1145/3642977.3652096
First, What Even Is Serverless and Why Containers?
Let me set the stage properly because the security problem only makes sense once you understand the plumbing underneath.
Serverless, at its core, is about breaking your application into small independent functions. Each function waits for a trigger, like an incoming HTTP request, wakes up, does its one job, and then goes back to sleep. The platform scales it up when there is demand and scales it all the way to zero when there is not. No idle servers burning money, no capacity planning headaches.
The way these functions get packaged and shipped is through containers. A container bundles your code with everything it needs, libraries, runtime, config, into one neat image. You can start a container in milliseconds. You can run hundreds of them on a single machine. Docker, containerd, runc these are the standard tools in this world, all governed by the OCI (Open Container Initiative) spec.
Containers are fast and efficient. Great. But here is the catch.
Containers share the host OS kernel. Every container on the same machine is talking to the same underlying kernel. The kernel manages memory, hardware access, process scheduling, everything at the lowest level. Containers get isolation through namespaces (which separate things like the process tree, filesystem view, and network) and cgroups (which limit CPU and memory consumption), but they are not running on separate kernels. They are just different "views" of the same kernel.
I've written a blog about building a container runtime from scratch https://kaizakin.site/blogs/container-runtime-from-scratch refer this for more information.
Think of it like living in an apartment building. Each tenant has their own unit, their own locked door. But the plumbing, the electrical grid, the building's foundation that is all shared. If someone floods their unit badly enough, it can become your problem too.
So what? CVEs related to container escapes and privilege escalation show up in security advisories regularly. A malicious or poorly written container can, under the right exploit, break out of its isolation and touch the host or other containers. For internal enterprise deployments where you trust your own developers, that risk is manageable. For a public cloud where literally anyone can submit code that risk is not manageable at all.
Knative's Honest Admission
Knative is one of the most widely used serverless frameworks in the cloud-native ecosystem. It sits on top of Kubernetes (K8s) and handles all the serverless-specific concerns: auto-scaling, scale-to-zero, request routing, lifecycle management. If you are running serverless workloads on Kubernetes, there is a good chance Knative is involved.
Here is what I respect about the Knative project: they are honest about their limitations. Their threat model documentation flat out states that they assume a single tenant per cluster. They do not consider themselves secure for multi-tenant scenarios where untrusted users are submitting arbitrary workloads.
That is a huge constraint. It means any provider that wants to use Knative for a real public serverless product needs to give every tenant their own dedicated cluster, which is expensive and operationally painful.
The mitigation Knative points to is enhanced isolation through sandboxed container runtimes. Which brings us to the two big options everyone reaches for.
FYI, this is what AWS lambda does, read
https://firecracker-microvm.github.io/
https://aws.amazon.com/blogs/compute/building-multi-tenant-saas-applications-with-aws-lambdas-new-tenant-isolation-mode/
gVisor and Kata Containers: Good Ideas With Real Costs
So the obvious move is to wrap your containers in something with stronger isolation. Two technologies dominate this space.
Kata Containers wraps each container inside a lightweight microVM. The container gets its own guest kernel running inside a virtual machine. Anything that container does, including system calls, is contained inside that VM. A container escape inside a Kata sandbox does not reach the host. The isolation is real.
The cost? Spinning up a microVM takes time and memory. You are booting a full guest OS for every container. For long-running services, that startup cost outweighs the lifetime of the container. For serverless cold starts, where the whole point is to respond to a trigger in under a second, booting a VM is painful.
gVisor takes a different angle. Instead of a full microVM, it inserts a user-space kernel between the container and the host OS. All syscalls made by the container, the read(), write(), socket(), mmap() calls that every program makes constantly, get intercepted by gVisor's user-space kernel (called Sentry) rather than going directly to the host kernel. If a container tries to exploit a kernel vulnerability through a syscall, gVisor catches it first.
The isolation is lighter-weight than Kata, but still meaningful. The cost is syscall interception overhead, which adds latency to every operation the container performs.
Both of these are legitimate solutions. Production-grade, widely deployed, battle-tested. But the researchers identified two problems that neither of them actually fixes.
Problem one: performance. The benchmarks are not kind. Both gVisor and Kata Containers roughly double the cold-start latency compared to plain containers. At the 99th percentile (which is what real users actually experience when things are slightly busy), gVisor hits 2.23 seconds and Kata Containers hits 3.91 seconds. Plain runc sits at 1.25 seconds. In serverless terms, that difference matters enormously.
Problem two: the internal boundary. This one is more subtle and I think it is the more interesting insight in the paper.
In Knative's architecture, every function pod has two containers running inside it. One is the user container, which holds the function code. The other is the queue-proxy, which is Knative's own infrastructure component. It handles request routing to the function, talks to the autoscaler, manages pod lifecycle signals. The queue-proxy is platform code, not user code.
When you sandbox a Knative pod with Kata Containers or gVisor, what you get is one sandbox with both containers inside it. The queue-proxy and the untrusted user function are sitting in the same isolated environment, separated from the host, but not separated from each other. If the user's code compromises something inside that sandbox, the queue-proxy is reachable. You've improved the external boundary but left the internal one completely unaddressed.
That is the gap this paper actually sets out to close.
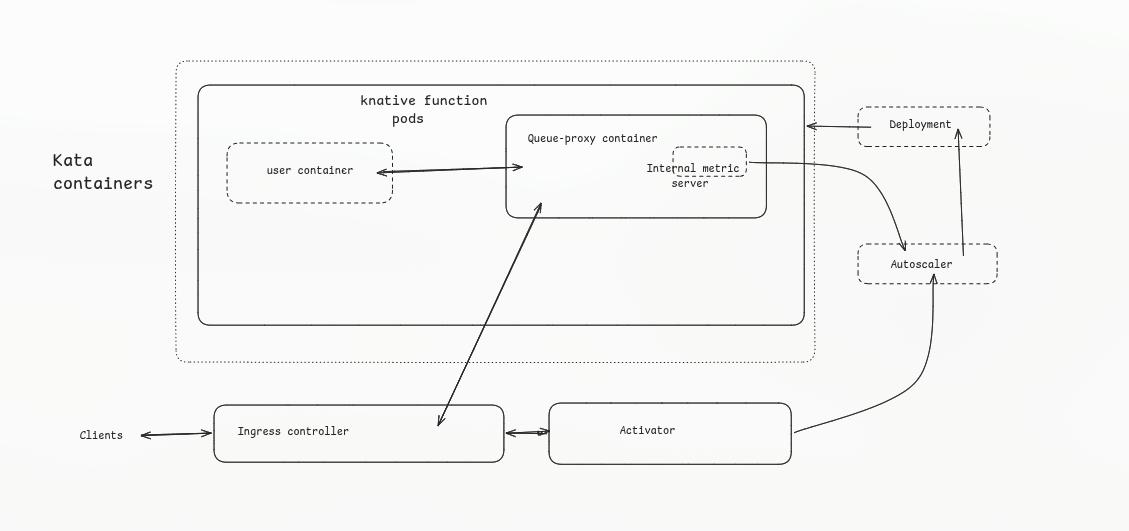
Okay, So What Even Are Unikernels?
Before I get into what the researchers built, let me explain unikernels properly, because I think most people have a vague sense that they are "lightweight VMs" and leave it at that. The actual concept is more interesting.
Think about what a general-purpose operating system has to do. It needs to support thousands of different applications. It needs drivers for hardware it might never actually have. It ships with a scheduler that handles dozens of concurrent processes, a filesystem stack that supports a dozen different formats, a networking stack that covers every protocol you can think of. It has a user management system, a permissions model, init systems, service managers. A minimal Ubuntu install is still over a gigabyte of code.
Your serverless function needs maybe 0.1% of that. It needs to open a socket, read a request, compute something, write a response. That is it.
A unikernel is what you get when you take that function and compile it together with only the specific OS components it actually needs into a single self-contained image. No unused drivers. No multi-user support (it is a single-application VM, why would there be multiple users). No layers. Just your application and the exact kernel primitives it requires, compiled together into one binary that boots directly into your app.
The result runs as a VM, so you get hardware-enforced isolation from everything else on the host. But the image is tiny, the attack surface is minimal (because there is almost nothing there to attack), and the boot time is in the milliseconds range because there is barely anything to initialize.
The tradeoff historically has been that unikernels are a pain to integrate with standard tooling. The container ecosystem has well-defined standards, OCI images, container runtimes, Kubernetes CRI. Unikernels have not traditionally spoken that language. That is exactly what the researchers decided to fix.
urunc: Teaching Kubernetes to Speak Unikernel
The tool they built is called urunc (unikernel container runtime). The goal is simple: let unikernels participate in a standard Kubernetes cluster without requiring any changes to the orchestration layer above.
urunc is an OCI-compliant low-level container runtime. It receives the same kind of requests that runc would receive, a container spec, a filesystem bundle, a set of annotations. Based on annotations on the container image, urunc decides what to do. If the annotation says this is a unikernel, urunc handles it by spawning the unikernel as a VM. If the annotation says this is a regular container, urunc passes it off to runc like normal.
This is the key architectural decision that makes everything else work.
As an engineer, you should appreciate what this gives you: a single container runtime that can manage both plain containers and VM-isolated unikernels transparently, within the same pod, without the orchestration layer knowing or caring.
Because urunc can handle both types within the same pod, you can now configure a Knative function pod so that the queue-proxy runs as a plain runc container while the user function runs as a unikernel VM. They co-exist in the same pod, they can still communicate over the pod's local network, but the user's code is now inside a hardware-isolated VM with a minimal attack surface. The queue-proxy is genuinely separated from the untrusted function, not just logically but at the hypervisor boundary.
This is what neither gVisor nor Kata Containers achieved. Both of those sandbox the entire pod. urunc sandboxes only the part that needs sandboxing, and it uses a much leaner runtime environment to do it.
Because of this, unikernels provided insansely low startup times
In a standard setup:
- Proxy gets Request -> Wait for standard Linux Container to boot (Slow) -> Send via Localhost -> Process.
In the urunc setup:
- Proxy gets Request -> Unikernel is already "Ready/Listening" (Fast) -> Send via Memory Pipe -> Process.
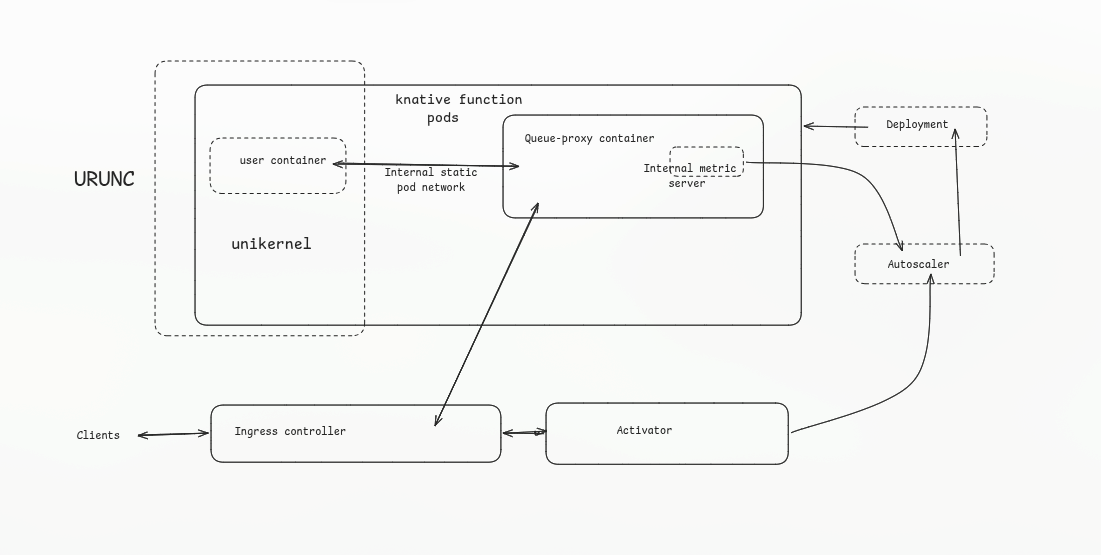
The Numbers
Let me just walk through what the benchmarks actually showed, because this is where the rubber meets the road.
Hardware: AMD EPYC 7502P (32 cores), 128GB RAM, bare metal. Software: Kubernetes 1.28, Knative 1.12, Ubuntu 20.04. Runtimes compared: runc, gVisor, Kata Containers, urunc. The benchmark tool is kperf, Knative's own benchmarking utility, which they customized to measure cold-start service response latency accurately.
Single instance, cold start:
runc averages around 1.2 seconds. urunc matches it almost exactly. gVisor and Kata Containers both sit in the 2 to 2.5 second range. At the 99th percentile: runc and urunc are identical at 1.25 seconds. gVisor is at 2.23 seconds. Kata Containers is at 3.91 seconds.
Scaling to multiple instances:
Up to 300 concurrent services, runc and urunc are indistinguishable. gVisor adds roughly 1.5 seconds of average overhead. Kata Containers starts degrading past 125 instances and above 200 instances shows more than 10x the latency of urunc. At 200+ concurrent services, Kata Containers is essentially unusable for serverless workloads.
Pushing to 500 instances:
Only runc and urunc were tested at this scale. Both spawned a comparable number of actual instances (some drop-off occurs due to cluster limits, not the runtime itself). urunc maintained low response latency even with 450 instances running simultaneously. Same memory and CPU footprint as plain runc, with VM-level isolation on the user container.
The "so what" here is not subtle. You get genuine hardware isolation, you close the internal queue-proxy vulnerability, and you pay zero performance cost compared to running completely unsandboxed containers. That is the trade-off that neither gVisor nor Kata Containers could offer.
What This Actually Means
unikernels have been "promising" for a while now. The research community has known they have good properties for serverless workloads. The gap has always been practical integration, nobody wants to throw away their entire container toolchain to use a different paradigm.
What this work demonstrates is that you do not have to. urunc slots into the existing Kubernetes CRI layer, speaks OCI, works with standard Knative, and requires no changes to how you orchestrate or deploy. The unikernel-specific stuff is entirely at the container runtime level, which is the right place for it.
There are still open questions. The benchmark uses a simple HTTP reply function, not a compute-intensive workload. Real serverless functions do database calls, machine learning inference, image processing. How unikernels behave under those workloads at scale is not covered here, and the researchers acknowledge they want to look at hardware acceleration next.
But the core claim is that unikernels can enable genuine multi-tenancy on Knative without sacrificing performance is backed by solid numbers. And the design insight about separating the queue-proxy from the user function is something that every Knative deployment dealing with untrusted workloads should be thinking about.
That is all from my side on this one.
Worth keeping an eye on urunc as it develops.